

The machines are trained using well “labelled” training data, and on basis of that data, machines predict the output.
The labelled data means some input data is already tagged with the correct output.
Supervisor is this training data (labelled data) which helps to predict the output correctly when a new input data point is given as input.
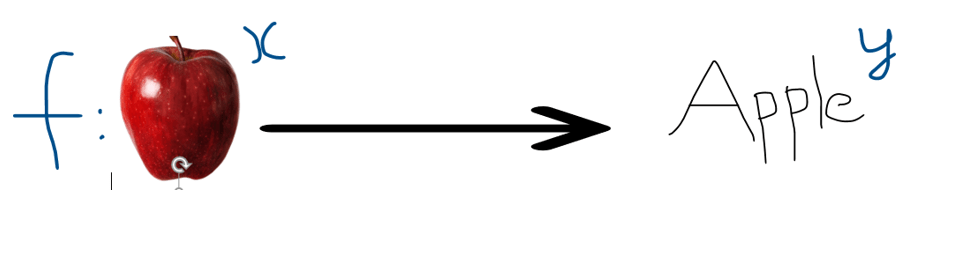
The aim of a supervised learning algorithm is to find a mapping function to map the input variable(x) with the output variable(y).
Step 1: The very first step of Supervised Machine Learning is to load labelled data into the system. This step is a bit time-consuming because the preparation of labelled data is often done by a human trainer.
Step 2: The next step is to train and build connections between inputs and outputs(function). This step is also known as the training model.
Step 3: Then comes the step known as the testing model. As the name suggests, you test the model by introducing it to a set of new data.
Here, the input is an independent variable, and the output is a dependent variable. The goal is to generate a mapping function that is accurate enough so that the algorithm can predict the output when we feed new input.
Example of labelled data:

We have a labelled dataset that consists of images of apples and oranges, with different attributes such shape, colour etc.
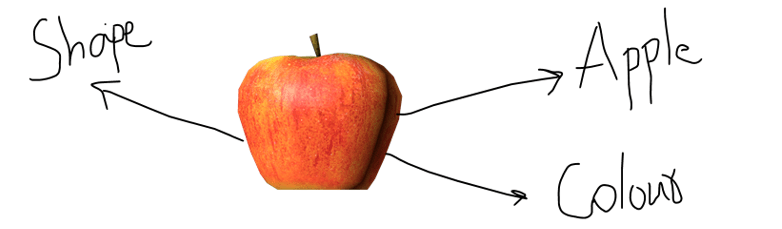
Consider the image of an apple shown above with the labels- shape, colour, and apple.
We train the model with this image. Then, we repeat the same training process with other images of both apples and oranges with their attributes.
What we are doing is-
Here, the input data is the independent variable and “Apple” or “Orange” is dependent variable as it is dependent on the input picture given.
Our goal is to generate a mapping function between the dependent and independent variable so we can determine the output when we feed a new data point.
Once the model is trained and the algorithm is built, the accuracy can be tested with the help of a test dataset.
When we feed the model with a new apple image, it scans the image and matches the attributes of the image with other trained images. Then depending upon the accuracy of the model, it returns the output ‘apple’.
When new data point is given as input, say,

The machine should be able to guess the output as “Apple”.
This labelled data or the training data (acts as supervisor), helps to predict the output as “Apple”.

You must be logged in to post a comment.