

The previous article was about the padding, stride, and parameters of CNN. This article is about the pooling and the procedure to build an image classifier.
Pooling
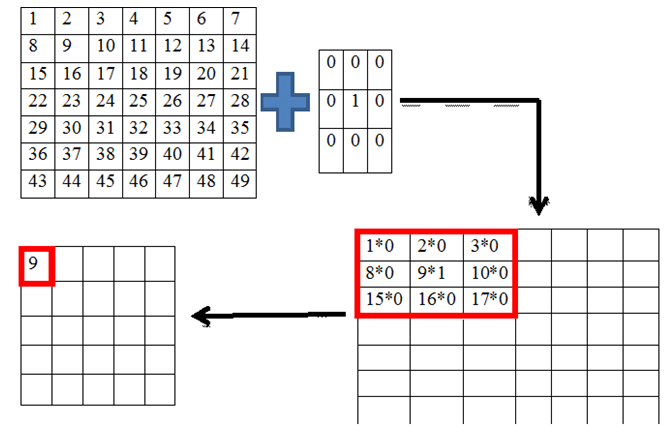
This is another aspect of CNN. There are different types of pooling like min pooling, max pooling, avg pooling, etc. the process is the same as before i.e. the kernel vector slides over the input vector and does computations on the dot product. If a 3*3 kernel is considered then it is applied over a 3*3 region inside the vector, it finds the dot product in the case of convolution. The same in pooling finds a particular value and substitutes that value in the output vector. The kernel value decides the type of pooling. The following table shows the operation done by the pooling.
| Type of pooling | The value seen in the output layer |
| Max pooling | Maximum of all considered cells |
| Min pooling | Minimum of all considered cells |
| Avg pooling | Average of all considered cells |
The considered cells are bounded within the kernel dimensions.
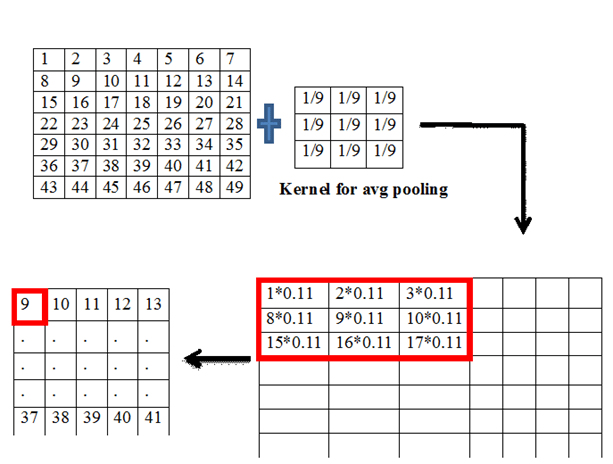
The pictorial representation of average pooling is shown above. The number of parameters in pooling is zero.
Convolution and pooling are the basis for feature extraction. The vector obtained from this step is fed into an FFN which then does the required task on the image.
Features of CNN
- Sparse connectivity
- Weight sharing.
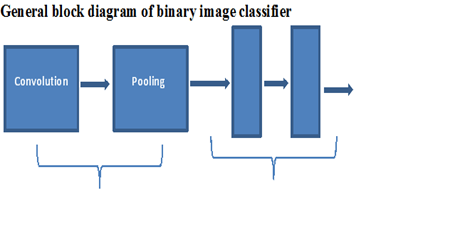
Feature extraction-CNN classifier-FNN
In general, CNN is first then FFN is later. But the order or number or types of convolution and pooling can vary based on the complexity and choice of the user.
Already there are a lot of models like VGGNet, AlexNet, GoogleNet, and ResNet. These models are made standard and their architecture has been already defined by researchers. We have to reshape our images in accordance with the dimensions of the model.
General procedure to build an image classifier using CNN
- Obtain the data in the form of image datasets.
- Set the output classes for the model to perform the classification on.
- Transform or in specific reshape the dimension of the images compatible to the model. The image size maybe 20*20 but the model accepts only 200*200 images; then we must reshape them to that size.
- Split the given data into training data and evaluation data. This is done by creating new datasets for both training and validation. More images are required for training.
- Define the model used for this task.
- Roughly sketch the architecture of the network.
- Determine the number of convolutions, pooling etc. and their order
- Determine the dimensions for the first layer, padding, stride, number of filters and dimensions of filter.
- Apply the formula and find the output dimensions for the next layer.
- Repeat 5d till the last layer in CNN.
- Determine the number of layers and number of neurons per layer and parameters in FNN.
- Sketch the architecture with the parameters and dimension.
- Incorporate these details into the machine.
- Or import a predefined model. In that case the classes in the last layer in the FNN must be replaced with ‘1’ for binary classification or with the number of classes. This is known as transfer learning.
- Train the model using the training dataset and calculate the loss function for periodic steps in the training.
- Check if the machine has performed correctly by comparing the true output with model prediction and hence compute the training accuracy.
- Test the machine with the evaluation data and verify the performance on that data and compute the validation accuracy.
- If both the accuracies are satisfactory then the machine is complete.


































You must be logged in to post a comment.