

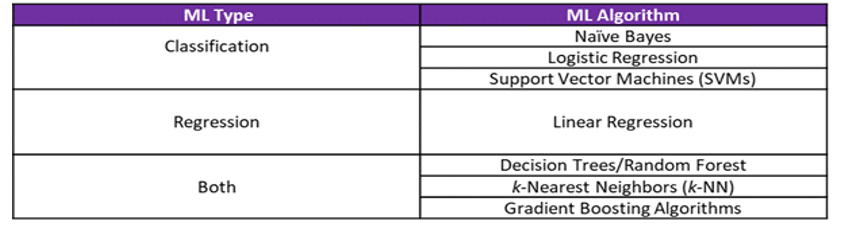
- Classification
Supervised learning can be further divided into two types of problems:
Classification algorithms are used when the output variable is categorical, which means there are two classes such as Yes-No, Male-Female, True-false, etc.
Multiple classes may also be present.
The output variable or the dependent variable should be categorical in nature.
Example: Diagnosis

“Prone to lung cancer” (output variable) is the dependent variable and “Weight” and “Number of cigarettes smoked” are the independent variables.
- Regression
Regression algorithms are used if there is a relationship between the input variable and the output variable. It is used for the prediction of continuous variables, such as Weather forecasting, Market Trends, etc.
- Analyse the existing data and
- Predict the future data parts.
Let’s say you have two variables, “Number of hours studied” & “Number of marks scored”. Here we want to understand how the number of marks scored by a student change with the number of hours studied by the student, i.e.
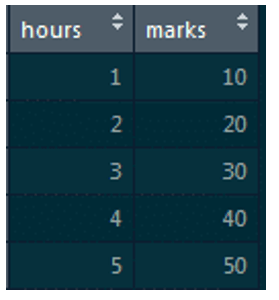
“Marks scored” is the dependent variable, and “Hours studied” is the independent variable.
You need to note that “marks scored” is the dependent variable and it is a continuous numerical.
Question: “How many hours should a student learn to get 60 points?”
Ans: The regression model would understand that there is an increment of 10 marks for every extra hour studied and to score 60 marks the student must study for 6 hours.
Example: Weather app in our mobile

This app predicts the weather of the entire next week. How does it do?
By analysing the previous data (say past 10 years weather report data) and predicts the pattern for the next week.
Here, since we deal with large amount of data, it may be difficult for humans to work on it. Hence, the machines are fed with large amount of data and made to predict the future data parts.

You must be logged in to post a comment.