

As the name suggests, unsupervised learning is a machine learning technique in which models are not supervised using training dataset.
Instead, models itself find the hidden patterns and insights from the given data.
It is much similar as a human learns to think by their own experiences, which makes it closer to the real AI.
In real-world, we do not always have input data with the corresponding output (training or labelled data referred to as supervisor). So, to solve such cases, we need unsupervised learning.
Steps:
Step 1: The very first step is to load the unlabeled data into the system.
Step 2: Once the data is loaded into the system, the algorithm analyses the data.
Step 3: As the analysis gets completed, the algorithm will look for patterns depending upon the behavior or attributes of the dataset.
Step 4: Once pattern identification and grouping are done, it gives the output.
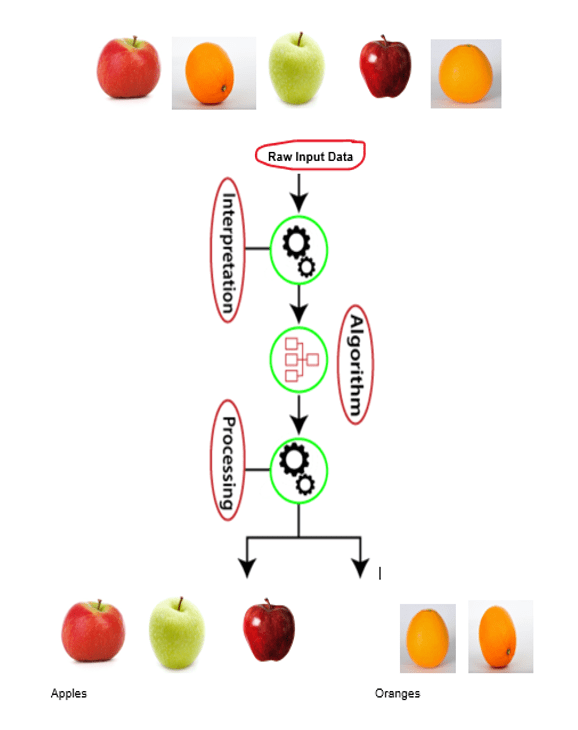
Example: Input dataset containing images of different types of fruits.

Now, let’s take these fruits and feed them to an unsupervised learning model.
The model determines the features associated with the data and understands that all the apples are similar in nature and thus groups them together.
Similarly, it understands that all the oranges have the same features and thus group them together and the same is the case with all the mangoes (in case we have mangoes in this example)
Here, the unsupervised learning algorithm will perform this task by clustering the image dataset into the groups according to similarities between images.
Example 2:
For instance, given a data base of movie reviews, you could identify clusters of users who rate action movies similarly, and use those correlations to predict how one member might like a particular movie he had not yet seen, but others have rated.

You must be logged in to post a comment.