
Public Perception of Corruption in the Police and Police-Community Relations in Ebonyi State, Nigeria
Egwu, Francis Ogbonnia
Department of Criminology and Security Studies, Alex Ekwueme Federal University, Ndufu-Alike, Ebonyi State, Nigeria Email: francis.egwu@funai.edu.ng
ORCID: https://orcid.org/0009-0009-8519-8303
Nlemchukwu Emmanuel Chigozirim
Department of Criminology and Security Studies, Alex Ekwueme Federal University, Ndufu-Alike, Ebonyi State, Nigeria Email: nlemchukwu.emmanuel@funai.edu.ng
ORCID: https://orcid.org/0009-0002-6403-6507
**Daniel Chidiebere Onwe**
Department of Criminology and Security Studies, Alex Ekwueme Federal University, Ndufu-Alike, Ebonyi State, Nigeria Email: onwedaniel1990@gmail.com
ORCID: https://orcid.org/0009-0003-4168-148X
Corresponding author***
Adinde, Kenneth Umezulike
Department of Criminology and Security Studies, Alex Ekwueme Federal University, Ndufu-Alike, Ebonyi State, Nigeria Email: kenneth.adinde@funai.edu.ng
ORCID: https://orcid.org/0009-0002-7458-7847
Igwe Kenneth Chiemeka
Department of Political Science, Alex Ekwueme Federal University,
Ndufu-Alike, Ebonyi State, Nigeria
Onyeacho Chike, ESQ
Department of Criminology and Security Studies,
University of Agriculture and Environmental Sciences, Umuagwo, Imo State
Izuogu Augustine
Department of Criminology and Security,
University of Agriculture and Environmental Sciences, Imo State
Nwadiani Grace Chinelo
Department of Criminology and Security Studies, Alex Ekwueme Federal University, Ndufu-Alike, Ebonyi State, Nigeria
Email: nwadianigracy@@gmail.com
Abstract
The present study examined public perception of police corruption and police community relationship in Ebonyi State, Nigeria. The study adopted quantitative method of data collection, sampling of 399 which comprises 243 males and 156 females, with stratified and simple random sampling technique. The study is anchored on structural functionalism theory as its framework. The findings of the study revealed that the public tends to dislike the police and as such, do not trust the police which in turn, alienates positive police-community relationship. The high practice of bribery, corruption, extortion and brutality on citizens impedes the trust and confidence of the public towards to the police. The study recommends that there should be periodic host of mutual police-community programme and festive by the police to enhance positive relationship with the public. Active team should be established and improved on proper surveillance, monitoring, evaluation and auditing the activities of the police force.
Keywords: Community Relation, Corruption, Police, Police-Community Relationship, Police Corruption
Introduction
The police is arguably the most visible agent of government and citizens often assess the character of a government through its police force. This is because the police are the “guardians” of society. To a large extent, the growth, actions and behaviours of the police as an institution, not only reflect the political and economic character of society, but also mirror what those in power are willing or able to tolerate or condone or perhaps even demand of the police. Thus any adequate analysis of the problems and challenges of the Nigeria Police must start with the appreciation of the history and dynamics of its development, which from its infancy in 1861 was characterised and cultured in impunity, incivility, brutality, a lack of transparency and accountability all of which eventually metamorphosed into large scale corruption. Corruption within the Nigeria Police is not unique. Corruption exists in the Nigeria Police Force much the same as it does in any other police organisation the world over, except perhaps, in terms of its extent and the organisation’s reaction to it. However, the issue of corruption in the Nigeria Police cannot be treated in isolation of the larger society. To achieve any success in combating corruption in the Nigeria Police one has to take a holistic approach and most importantly understand the growth and existence of corruption within the police (ICPC, 2008)
Corruption in the police organisation is not just limited to Nigeria as it also has global antecedent. In Palestine, It has been repeatedly asserted by a number of observers and monitoring organizations that corruption within Palestinian institutions (public, private, and civil society organizations) is prevalent (ICHR, 2012a, Ramahi, 2013, AMAN, 2013). According to several opinion polls and recent reports, Palestinian police were reported to be involved in “patronage, nepotism, and favoritism”, “prejudice”, “police brutality”, and “waste of public funds” (ICHR, 2012a; AMAN, 2012). They were rarely reported to be involved in other serious forms of corruption such as bribery, “the fix”, and “direct criminal activities”. In spite of this, the subject of police corruption has received very little attention in the research literature on Palestine. This may be due to a number of reasons. As with most police organizations, the Palestine police leaders might not be open to having outside researchers investigate such a sensitive topic. Police officers within the Palestine police might also be reluctant to discuss corruption for fear of damaging the image of the Palestinian struggle against the occupation and other possible fallouts. Finally, the nature and extent of police corruption are difficult to capture and gauge accurately using empirical methods.
In contemporary Nigeria, the public sees the police as an instrument and face of the government in power that is always ready to unleash terror at the slightest opportunity, hence they are held in low regard and do not enjoy the habitual cooperation of the public. The public perception of the police is not shaped by the kind of job they are called upon to do but by the attitude of the personnel. Their roles in many cases denigrate the law, endangering the citizens and blotting the institutional reputation of the police that they represent. The police no doubt know that they are not liked by the public, despite the fact that they risk their lives to protect them. At the very slightest opportunity, they are booed and jeered at by the public who call them derogatory and disgusting names. This dislike or resentment of the police apparently has some bearing on Nigeria Police colonial history. The police are conceived, not as a service organization for native, because of the use to which the colonial masters put the police that were harassing and arresting tax defaulters, brutalizing trade unionists and other nationalists, and torturing persons accused of criminal offences, nobody wanted to have anything to do with the police. It will be seen, therefore, that from the beginning, a serious communication gap was built between the police and the public and this mutual distrust rather than disappear has continued to grow wider. The situation is so bad that it became fashionable for parents to threaten their unwary and troublesome children with police presence (Odu cited in Asemota, 2012). The unfortunate mundane picture of the police painted here by the public has created serious problems for the police/public relations.
Brief Overview of Nigeria Police and Police-Community Relationship
What is today known as the Nigeria police force is the brainchild of the British colonial government and it dates back to 1861, following the annexation of Lagos (Tamuno, 1970). Although various nationalities all had their local ways of policing before the advent of the British colonialists, but such arrangements were based on a part-time basis. Most of these police were not paid formal salary; they got their rewards from gifts and gratifications in an informal way and they were natives of the area they policed. Dambazau (2004) noted that the Nigeria police, from inception, was not put in place to protect the interest and as well as the wellbeing of the people. The Nigerian police was borne out of the desire by the British colonialists to protect themselves, their interest and their trade. The British consul charged with the administration of Lagos established a Consular Guard in Lagos by the Police Act of 1861 to maintain law and order. In 1861, the 30-member Consular Guard was renamed Hausa Guard. It was further regularized in 1879 by an ordinance creating a constabulary for the Colony of Lagos thus the Hausa Guard became known as Hausa Constabulary and its men mainly drawn from among the Hausa ethnic group. The constabulary was mainly military in character, though it performed some police duties (Tamuno, 1970).
In 1861, the Lagos Police Force was created and armed like the Hausa Constabulary. With the proclamation of Northern and Southern protectorates in 1914 until 1930, they were merged to form the present Nigeria Police Force with headquarters in Lagos (Tamuno, 1970). In 1943, the Northern and Western Regions of Nigeria established their own regional police forces. All the northern and southern protectorates police forces were merged with the Nigeria Police Force in 1968 and with the creation of Abuja as Federal Capital Territory in 1976, the headquarters of Nigeria police shifted from Lagos to Abuja ( Alemika & Chukwuma, 2000). Currently, the Force Headquarters of the Nigeria Police is located at Shehu Shagari Way, Abuja Federal Capital Territory (FCT). Since 1976, the Police Force has been undergoing series of structural changes. Like promotion, establishment of departments more zonal and state commands, divisions and special branches to checkmate its public relations and consequently upsurge of crime in the country. Police cannot perform their duties without having a good relationship with the community wherein they serve. Similarly, the community will live in absolute anxiety and fear of attack without police. There is need to maintain and sustain a mutual relationship between the police and public in the society. Akpotu (2003) contends that the Nigeria police have a very poor relationship with people right from time. This is as a result of corruption, envy and brutality that they mete out to the people. In any rally or demonstration, they turn to fuel the event by shooting the public. Mbachie (2005) lamented that the practice of the police does not help matters in promotion of cordial relationship with the public. The police cause many accidents that claimed lives through their checkpoints on the roads. Ehon (2003) also asserted that the culture of monetization and the tendency to get rich quick among members of the police force have affected their relationship with the public. He further expressed his feeling that police do not believe in hard work; they have thrown the values of the society into the dustbin. With the above stated problems, the public seem to perceive the police as enemies. This has made the police to come out with some programmes aimed at establishing a cordial and friendly relationship with the public. Yecho (2005) maintains that the police enforce law in a way that is essentially indiscretion. According to him, they seek to favour culprits who are highly influential in the society to the detriment of the common masses. They appear blind to justice and equity and consequently twist the law to suit their selfish interest. By implications, the police rather than effectively controlling crime are actually in the habit of violating the laws of criminal justice system in order to protect those in high positions and control of power and resources (Yeche, 2005). Adesina (2003) sums it up that police-community relationship in Nigeria has been a poor one. The police are disliked instead of liked, distrusted instead of trusted, hated instead of loved. They cause disharmony instead of harmony and this has resulted in total loss of confidence by the public in the Nigeria police. This has become evident of the poor police-public relations in Nigeria.
A good rapport and goodwill between police and the public enable police to serve the public better and the public also feel better. Black (2011) maintains that under modern conditions, no government organization of any kind can operate successfully without the cooperation of its publics. These publics may be both at home and overseas, but mutual understanding will be a potent factor for success in every case. The police require knowledge on how the community operates in order to take full advantage of the facilities and services provided by the police. There is clearly need for good police public relationship to help citizens understand the responsibilities of Nigeria Police Force in the society. Good police public relations enables the police to have a better understanding of the public’s concerns especially crime related issues, and citizens are more inclined to report crimes that occur to the police, provide tips and intelligence to the police, willingly serve as witnesses, and happily participate in criminal justice system. Incidentally, police also become more proactive thereby preventing crimes before they occur or minimizing their impact, instead of simply reacting to calls for service from members of the public. Good police-public relations prevents the possibility that the pubic think that police are simply a mechanism for intelligence collection and as such denying them vital information that would aid in crime detection, prevention and apprehension of criminals. Poor police public relations denies the police basic understanding of public problems, goals, desires, and in turn the public also are denied access to the police especially those in need of the police services. They perceive police as an agent that occupies an out-of-touch force that does more harm than good to the public. In these situations, police rarely assume a reactive mode of response to public problems. It is evident that the Nigeria police are highly and visibly subservient to the rich and powerful, even in the rendering of services and as such spoiled their relationship with the public. The Nigeria police have engaged themselves in much brutality on the poor masses. In this way, they hinder the desired public cooperation. Finally, public participation involves members of the public taking an active role in trying to genuinely help the police to illicit information on the whereabouts of criminals in the society. Indeed, the failure of the police in Nigeria and other developing countries generally can be traced to ignorance, lack of trust by the public and the total uncooperative posture due to police insensitivity to the suffering of the people. The police should stop being snipers but learn to stop snipers in Nigeria. Benjamin (2001) also points out that the police have not been useful nor helpful in promoting its image before the general public, as there are many cases of murder, assassination, and robbery which took place in the society that have lasted for two or more years without the police’s identification of the culprits, let alone arresting and prosecuting such groups or gangs. The failure of the police according to Benjamin to either apprehend killers of robbery victims and assassins all over the county has apparently reinforced the belief of critics who describe the police force as dubious, corrupt, inept and brutal.
Objectives of the Study
The following research questions were formulated to guide the study;
1. Ascertain the public perception of police corruption on police-community relationship in South East, Ebonyi State, Nigeria?
2. Identify factors responsible for the poor state of police-community relationship in South East, Ebonyi State, Nigeria?
3. Suggest possible measures could be adopted to curb police corruption and enhance police-community relationship in South East, Ebonyi State, Nigeria?
Concept of Police-Public Relation
Public Relations refers to a management function of a continuing and planned character, through which public or private organization and institution seek to win and retain the understanding, sympathy, and support of those with whom they are or may be concerned by evaluating public opinion about themselves, in order to correlate as far as possible, their own policies and procedures to achieve by planned and widespread information, more cooperation and more efficient fulfillment of their common interests (IPRA at the Hague, 1960 as cited in Keghku, 2005). Public relations entail the management function which evaluates public attitudes, identifies the policies and procedures of an individual or an organization with the public interest, and executes a programme of action to earn public understanding and acceptance (Grisworld, 1977 in Keghku, 2005). Black (2011) defines public relations as a practice and the art of analyzing trends, predicting their consequences, counseling organization’s leadership, and implementing planned programmes of action which will serve both the origination and the public interest.
Police-community relations refers to a management function of a planned and continuing character whereby the police as a public institution seek ways to win and retain the understanding, sympathy, support, and co-operation of members of the public both as individuals and a collectivity towards effective discharge of their statutory responsibilities as a crime prevention and fighting outfit in society (Chukwuma, 2005). As a corollary to the foregoing, in the police-public relations endeavour, it is not only the police that make the move but also the public who are also expected to embrace every move by the police towards establishing cordial relations between the two parties in the efforts at crime fighting and prevention of social disorder. The foregoing -shows that any meaningful police-public relations is expected to be a two-partite move towards cooperation and support for crime fighting and social disorder prevention. That is n to say, like in the case of corporate image management in business administration, police-public relations as an endeavour should not be “monologic” (coming from one party) but “dialogical” in nature (Massey, 2013). Worthy of note here again is the relationship between the two concepts of police-community relations and community policing. All too often since the mid 1980s it made its debut into the Nigerian soil as an attempt to strengthen the obvious decline in the capability of the conventional police to stem the rising wave of criminality across Nigeria, the concept and practice of community policing has been widely confused with that police public relations. The point is that while police-community relations is an integral part of the larger practical project known as community policing, the two mean different things. For instance, while police-community relations is an intangible attitudinal construct, community policing is a practice that entails police-community partnership and community problem solving (BJA, 2008).
Factors Impeding the Effectiveness of Police-Community Relationship
There is no doubt that the effectiveness and efficiency of the Nigeria police have been under stress and adversely affected by various problems such as inappropriate policing orientation and strategies with emphasis on reactive instead of proactive/preventive measures, brutality against citizens, including extrajudicial killing, corruption and extortion, poor performance in the areas of intelligence analysis and utilization as well as investigation and perversion of the course of justice etc (Jike, 2003; Ekpeyong, 1987; Alemika, 1993; Onoge, 1993). Onoge (1993) observed that the sloganeering “Police is your friend” in present-day Nigeria notwithstanding, the rival popular image of the police as corrupt “kill and go” squad has not abated. Onoge wondered that despite three decades after independence Nigeria still quests for a social order based not on brute force but on just and moral consensus. Violence, inter-communal and religious conflicts remain, corrupt looting of the national treasury continues to occur, all sorts of violent crime are committed with reckless abandon in the full glare of the police statutorily charged with public peace and order maintenance; all of these signal the lack of commitment to orderly development of the Nigeria socio-political space (Onoge, 1993). Till date, it is somehow very disturbing that despite the constitutional powers granted the police to maintain public peace, safety and general security in Nigeria, the quality of security has nothing to be proud of and it has no doubt generated a great deal of controversies (Odekunle, 2004) Odekunle declared “ Nigeria police force falls short of optimum performance”. This is manifest in the widespread inefficiencies, corruption, unfairness in dealing with suspects, occasional over-use of legitimate force, bad temper, bullying, and other abuses of citizen’s rights with impunity. The Apo six killings in Abuja by the police in 2005 is an example (Brewier, Gueke, Hwne, Moxon-Browne and Wilford, 1996). Ekpeyong (2007) argued that there were reports of some crimes committed with the connivance or participation of the police. This is also evident in „how the police protect robbers: a victim’s account‟ in Tell Magazine, December 31, 2001. It was reported in this paper that some of the special Anti Robbery squad of the Nigeria police, Lagos command, struck a deadly partnership with armed robbers, helping them escape justice and threatening the lives of victims who make efforts to recover their stolen property. Ekpeyong also observed that there were cases of alleged destruction of crime evidence and reports by the police, arrested persons released, criminal charges and prosecutions dropped in exchange for bribes or other benefits. Ekpeyong also averred that false charges were reportedly made against innocent and ignorant citizens, criminal investigations suspended and other abuse of rights with impunity were rampant among the police. The poor educational attainment, the lack of the requisite professional qualification, the recruitment of low-skilled persons, and low salary scale which had lagged behind the national minimum for several years but until now, is allegedly at the root of the misdeeds of the police and high attrition rates (Ekpeyong, 2007). In line with the police inefficiency, Orobator (1993) observed that the problem of under-funding is not peculiar to the police, but said it will remain a recurring problem so long as the supply of national resources cannot meet the demand for social services. From this point, however, the under-funding of the Nigeria Police has reduced their state of preparedness and level of efficiency to a pitiful level. The acute shortage of accommodation for the policemen made the co-ordination of their activities difficult and this adversely affected their performance. Orobator maintained that the police cannot be said to be better off in terms of equipment, radio and other communication facilities that can hardly be relied upon, as their capacity for mobility is at best close to zero. He said, cases of an entire Police Division having only a vehicle, which is usually not always road-worthy, are abundant and indeed there are stations without vehicles at all. The end result, according to Orobator (1993), is that the Nigeria Police Force is not adequately equipped for its job; the nonchalant attitude to work is an additional factor that has aided the inefficiency of the police in crime prevention and control in Nigeria. Alemika (2003) was of the opinion that agencies of crime management in Nigeria share in common certain problems such as authoritarian or repressive legacy and orientation, lack of consultation with and accountability to citizens; lack of policies that specifically harmonize their operations with democratic principles of criminal justice system; poor funding of activities; poor staffing and inadequate remuneration of staff; inadequate resources; insensibility/insensitivity and thereby non-utilization of scientific research, knowledge and expertise in the various academic fields of criminology, forensic criminology, police science, Psychology, penology, sociology of law, criminal justice and law enforcement to improve training, planning, operations, monitoring and evaluation; corruption; lack of institutionalized mechanisms by which the agencies are answerable to the public for their activities and lack of coordination to achieve efficiency (Alemika, 2003).
Theoretical Framework
This study is anchored on the extant theory of Talcott Parsons 1956 Structural Functionalism. Functionalism draws its inspiration from the ideas of August Comte (1798-1857), Herbert Spencer (1820-1903), Talott Parson (1920-1979), Emile Durkheim (1858-1917) and Robert Merton (1910-2003). Functionalism is a theory that sees society as a complex system whose parts work together to promote solidarity and stability (Macionis, 2010). This perspective looks at society through a macro-level orientation, which is a broad focus on the social structures that shape society as a whole, and believes that society has evolved like organisms (DeRosso, 2003). The theory is of the view that both social structure and social functions are performing in the society. Functionalism addresses society as a whole in terms of the function of its constituent elements, namely, norms, customs, traditions, and institutions. A common analogy, popularized by Herbert Spencer, presents these parts of society as “organs” that work toward the proper functioning of the “body” as a whole (Vrry, 2000). For example, each of the social institutions contributes important functions for society: Family provides a context for reproducing, nurturing, and socializing children; education offers a way to transmit a society’s skills; knowledge, and culture to its youth, politics provides a means of governing members of society; economics provides for the production, distribution, and consumption of goods and services; and religion provides moral guidance and an outlet for worship of a higher power; while police provides for security of lives and property. The functionalist perspective emphasizes the interconnectedness of society by focusing on how each part influences and is influenced by other parts. For example, the increase in poor police-public relations will increase the level of crime the society and vice versa. Functionalists use the terms functional and dysfunctional to describe the effects of social elements on society. Elements of society are functional if they contribute to social stability and dysfunctional if they disrupt social stability. Some aspects of society can be both functional and dysfunctional. For example, crime is dysfunctional in that it is associated with physical violence, loss of property, and fear. But according to Durkheim and other functionalists, crime is also for society because it leads to heightened awareness of shared moral bonds and increased social cohesion. So police-community relations play a crucial role in controlling crime of corruption. Police public relations allows people to volunteer information to the police about criminal hideouts as such enabling the police to carry out their functions of crime detection, prevention and apprehension of criminal, thereby effectively maintaining a functioning society. The structural functionalist theory will be adopted as a theoretical guide for the study due to its relevance to the topic of discussion.
Methodology
Study Design, Study Frame and Sample Size
The study employed descriptive survey design. Descriptive survey gives a clear picture of a situation and it serves as a basis for most researchers in assessing the situation as a prerequisite for drawing conclusion. According to Nwankwo (2006) descriptive survey is a research method which focuses on a representative sample derived from the entire population. This design was adopted because of its ability to ensure a representative outlook and provide a simple approach to the study of opinions, attitude and values of individuals. The study area was Ebonyi Metropolis, South-East, Nigeria. The area is made up of thirteen local government. The researcher’s choice of Ebonyi Metropolis was informed by the prevalence of corrupt practices among the police officers on duty. The total population was 214,969, from which a sample of 400 was selected using Taro Yamen formula for sample determination.
Data Collection and Setting and Data Analysis
The instruments for data collection were questionnaire and In-depth Interview (IDI). The questionnaire was used in collecting quantitative data. For the quantitative data, questionnaires were processed using as Statistical Package for Social Sciences version 20.0. Descriptive statistics such as frequencies, percentages and tables were used for data analysis. The qualitative data were processed using content analysis.
Results
The responses were presented in tables and respondents were asked on how they perceived police corruption on police-community relationship in South-East, Ebonyi State, Nigeria.
| S/N | ITEMS | Strongly Agree | Agree | Disagree | Strongly Disagree | Mean | Decision |
| 1 | The police are said to be the people’s friend, this assertion often plays in reality. | 52 | 40 | 117 | 190 | 1.88 | Rejected |
| 2 | The public have trust issues on the police and as such, do not have positive relationship with them. | 200 | 111 | 36 | 52 | 3.15 | Accepted |
| 3 | The public sees the police as their friend in whom they have full confidence in. | 40 | 33 | 120 | 206 | 1.77 | Rejected |
| 4 | Police are corrupt in it’s dealings and regarded as trigger-happy by the public. | 201 | 100 | 49 | 49 | 3.14 | Accepted |
| 5 | Due to the involvement of the police in bribery, extortion and other corrupt practices, it breeds negative relationships with the public. | 250 | 78 | 33 | 38 | 3.35 | Accepted |
Field Survey, 2025
From the field survey, the public decline the notion that “police is your friend” thereby depicting that there is no friendly atmosphere of relationship existing between the public and the police. The public tends to dislike the police and as such, do not trust the police which in turn, alienates positive police-community relationship. The police are regarded by the public, as corrupt and trigger-happy agency whom often infringe on enshrined fundamental human rights. The study also reveals that, the negative relationships between the police and public, stems from bribery, corruption and extortion imminent in the police.
Table 9: Identify Factors Responsible for the Poor State of Police-Community Relationship in Ebonyi State.
| S/N | ITEMS | Strongly Agree | Agree | Disagree | Strongly Disagree | Mean | Decision |
| 1 | The high practice of bribery, extortion and brutality on the citizens has often impede the trust and confidence on the police. | 215 | 99 | 51 | 34 | 3.24 | Accepted |
| 2 | The dented relationship of the police and public is caused by the high practice of corruption imminent in the organization | 199 | 125 | 40 | 35 | 3.21 | Accepted |
| 3 | Lack of professional practices and conduct in matters regarding the public renders poor police-community relationship. | 189 | 111 | 36 | 63 | 3.07 | Accepted |
| 4 | Absence of proactive policing and lack of intelligence leading to arrest of innocent people causes loss of confidence in the police by the public. | 230 | 89 | 54 | 26 | 3.31 | Accepted |
| 5 | Lack of community oriented programmes organized by the police to boost synergy and foster healthy relationships. | 225 | 111 | 25 | 38 | 3.31 | Accepted |
Field Survey, 2025
Table 9 tends to identify the reason for the poor state of police-community relationship. As seen above, the table contains five statements. All the statements contained in the table were accepted following proper mean score analysis. This implies that, there wholesome agreement with the information depicted by the researcher. The study reveals that, the high practice of bribery, corruption, extortion and brutality on citizens impedes the trust and confidence of the public towards to the police. The police are said to act unprofessional in discharging their duty which in turn questions their credibility level by the public, making the public not to have friendly relationships with them. The inability of the police to be proactive in crime prevention and poor intelligence leading to arrest of innocent people also contribute to the poor state of police-community relationship in Ebonyi State. Finally, the police lacks community oriented programmes and do not invest in initiatives that will enhance and foster healthy relationships with the public.
Possible Measures Adopted to Curb Police Corruption and Enhance Police-Community Relationship in the Area.
| S/N | ITEMS | Strongly Agree | Agree | Disagree | Strongly Disagree | Mean | Decision |
| 1 | There will be an effective police-community relationship if proper solutions are developed and implemented. | 232 | 85 | 32 | 50 | 3 .25 | Accepted |
| 2 | If the police conducts themselves in a professional manner in discharge of their role, there will be enhancement in it relationship with the public. | 240 | 100 | 30 | 29 | 3.38 | Accepted |
| 3 | The police should set up an active public complaint unit that will swiftly address community complains on erring officers. | 190 | 140 | 33 | 36 | 3.21 | Accepted |
| 4 | Proper check should be done on the activities of the road side policemen to penalize those involve in extortion and bribery. | 151 | 200 | 29 | 19 | 3.21 | Accepted |
| 5 | Police officers renumeration should be increased to meet up to average living conditions to caution bribery tendencies. | 250 | 65 | 44 | 40 | 3.32 | Accepted |
| 6 | Periodic host of mutual police-community programme and festive by the police will not enhance positive relationship with the public. | 33 | 54 | 150 | 162 | 1.89 | Rejected |
Field Survey, 2025
Table 10 of this study suggests possible solution or measures that can be put in place to halt police corruption and enhance police-community relationship in South-East, Ebonyi State, Nigeria. From the above, the table contains six statements. All the statement were accepted except for statement 6 which was rejected, showing a total disapproval with the information therein. The study reveals that if the police conduct themselves in a professional manner while showing respect for human rights will definitely enhance public trust and confidence in them, thereby strengthening the relationship amongst both parties. The need for the police leaders to set up a working and effective public complaint unit to swiftly respond to public complaints will also strengthen positive relationship with the community. There should be a proper surveillance and check on the conduct and activities of the roadside officer to ensure higher standards of professionalism while discharging their duties. The need for increase in the salaries and renumeration of officers should be implemented so as to curb corruption and bribery due to poor living standards. Lastly, the police should organize frequent or periodic community-oriented programmes that will serve as avenue for togetherness of the public with the police. For such will instill confidence and trust in the heart of the public.
Discussion of Findings
The public revealed that the notion of “police is a your friend” does not play in reality as the public dislike the police. It is a love-hate relationship. This depicts that there is no friendly atmosphere of relationship existing between the public and the police. The public tends to dislike the police and as such, do not trust the police which in turn, alienates positive police-community relationship. The police are regarded by the public, as corrupt and trigger-happy agency whom often infringe on enshrined fundamental human rights. The negative relationships between the police and public, stems from acts of bribery, corruption and extortion imminent in the police.
Onoge (1993) observed that the sloganeering “Police is your friend” in present-day Nigeria notwithstanding, the rival popular image of the police as corrupt “kill and go” squad has not abated. Onoge wondered that despite three decades after independence Nigeria still quests for a social order based not on brute force but on just and moral consensus. Till date, it is somehow very disturbing that despite the constitutional powers granted the police to maintain public peace, safety and general security in Nigeria, the quality of security has nothing to be proud of and it has no doubt generated a great deal of controversies (Odekunle, 2004).
Findings from the study also emphasized on the high practice of bribery, corruption, extortion and brutality on citizens by the police which in turn, impedes on the trust and confidence of the public towards to the police. The police acts unprofessional in discharging their duty as such, questions their credibility and effectiveness level by the public, making the public not to have friendly relationships with them. Another factor also reiterated on the study findings is the inability of the police to be proactive in crime prevention and poor intelligence which most times leads to arrest of innocent people. This unprofessional act contributes to the poor state of police-community relationship in Ebonyi State Metropolis. Finally, the police lacks community oriented programmes and do not invest in initiatives that will enhance and foster healthy relationships with the public.
Odekunle (2004) declared “Nigeria police force falls short of optimum performance”. This is manifest in the widespread inefficiencies, corruption, unfairness in dealing with suspects, occasional over-use of legitimate force, bad temper, bullying, and other abuses of citizen‟s rights with impunity. The poor educational attainment, the lack of the requisite professional qualification, the recruitment of low-skilled persons, and low salary scale which had lagged behind the national minimum for several years but until now, is allegedly at the root of the misdeeds of the police and high attrition rates (Ekpeyong, 2007). Ineffectiveness of the police are contributed by poor funding of activities; poor staffing and inadequate remuneration of staff; inadequate resources; insensibility/insensitivity and thereby non-utilization of scientific research, knowledge and expertise in the various academic fields of criminology, forensic criminology, police science, Psychology, penology, sociology of law, criminal justice and law enforcement (Alemika, 2003).
The study also found out there is need for the policemen to conduct themselves professionally. Most especially the roadside officer. If the police conduct themselves in a professional manner while showing respect for human rights, it will definitely enhance public trust and confidence in them, thereby strengthening the relationship with the public. Police leaders should set up a working and effective public complaint unit which will swiftly respond to public complaints, in turn strengthens positive relationship with the community. There should be a proper surveillance and check on the conduct and activities of the roadside officer to ensure higher standards of professionalism while discharging their duties. There should be an increment in the salaries and renumeration of officers in order to curb corruption and bribery tendencies caused by poor living standards. Police should organize frequent or periodic community-oriented programmes that will serve as avenue for togetherness of the public with the police. This friendly atmosphere will imbibe trust and confidence of the police into the people.
Orobator (1993) observed that the problem of under-funding is not peculiar to the police, but said it will remain a recurring problem so long as the supply of national resources cannot meet the demand for social services. From this point, however, the under-funding of the Nigeria Police has reduced their state of preparedness and level of efficiency to a pitiful level. Shortage of accommodation for the policemen made the co-ordination of their activities difficult and this adversely affected their performance. Orobator maintained that the police cannot be said to be better off in terms of equipment, radio and other communication facilities that can hardly be relied upon, as their capacity for mobility is at best close to zero. Alemika (2003) was of the opinion that police in Nigeria is bedeviled with problems such as authoritarian or repressive legacy and orientation, lack of consultation with and accountability to citizens; lack of policies that specifically harmonize their operations with democratic principles of criminal justice system, poor planning, operations, monitoring and evaluation; corruption; lack of institutionalized mechanisms by which the agencies are answerable to the public for their activities and lack of coordination to achieve efficiency.
Conclusion
Regardless of cultural, political, or socioeconomic background, the vast majority of people have one thing in common: to live in a peaceful and prosperous community. A sense of safety and belonging are fundamental to any human’s needs, and without this, it becomes difficult to prosper and develop their best self. Integral to that sense of peace and safety is the relationship between law enforcement and the community in which they live and serve. Police-community relations is a term that can encompass everything from the physical interactions between officers and civilians to the intangible emotions between them such as respect and trust. Essentially, police-community relations are the relationship between the police and the communities they serve. Healthy police-community relations are synonymous with a healthy community.
In general, police-community relations is the relationship between the police and the communities they serve. Both officers and civilians in the community depend on these to be healthy and strong to best preserve public safety and uphold justice. Sadly, there have been longstanding practices in many police departments that have fractured the public trust, such as corruption and using high arrest numbers as a metric for gauging success in departmental evaluations.
Recommendations
In line with the findings of the study, the following recommendations are made:
1. Periodic host of mutual police-community programme and festive by the police will not enhance positive relationship with the public. This should be a community-oriented programme aimed at harmonizing the police and public towards working in one accord. This will also present a friendly atmosphere allowing positive union in an informal setting between the public and the police.
2. There is a dire need for the renumerations and allowances of the police to be looked into. Just like the assertion posits “a hungry man is an angry man”. If a police officer is waged on poor renumeration, such person will transfer aggression to the public it is policing by extorting them thereby escalating corrupt practices.
3. The establishment and improvement of proper surveillance, monitoring, evaluation and auditing team within the police force. This team will serve in the area of checkmating the activities of the police officer, even those on road side. They will specialize in giving listening ear to the public on their complaints without delays.
References
Adesina, A. (2013). Attitudes and Beliefs of the Families of Policemen to the Nigeria Police, in Jike, V.T (Ed), The Nigeria Police and the Crisis of law and Order Lagos, NISS Publications.
Akpotu, N.E. (2003). The Cost of Campus Violence and the Maintenanc e of law and Order in
Nigeria Universities, in Ike, V.T (Ed) The Nigeria Police and the Crisis of Law and Order,Lagos: NISS Publications.
Alemika, E.E.O.(2003). The politics of identities and democracy in Nigeria, Jos: University of
Jos.
Alemika, E.E.O. & Chukwuman, I. (2000). Police community violence in Nigeria. Lagos: Centre
for Law Enforcement Education and Human Rights Commission.
AMAN (2013). Opinion Poll on Corruption in Palestine for the Year 2012. Ramallah, Palestine:
The Coalition for Accountability and Integrity (AMAN).
Benjamin, S.A. (2001). Federalism, Identity Crisis and Resurgent Nationalism in Fourth
Republic. Paper presented to the sustainable democracy in Nigeria NISER. Ibadan. May 31.
Black, S. (2011). Introduction to Public Relations, Lagos West African Book Publishers Ltd.
ICHR (2012a). The Status of Human Rights In Palestine: The Eighteenth Annual Report.
Ramallah, Palestine: Independent Commission for Human Rights (ICHR).
ICPC (2008). Combating Corruption in the Nigeria Police. A Presentation By the Independent
Corrupt Practices & Other Related Offences Commission At the Police Service Commission Retreat August ‘08
Jike, V.T. (2003). The Nigeria Police and the kaleidscope of manifest and latent functions.
Journal of the Nigerian Sociological Society Vol. 1(2), p. 58-68.
Keghku, T. (2005). Public Relations and Nigerian Economy; Makurdi, Aboki Publisher.
Massey, J. E. (2013). A theory of organization image management: antecedents, processes and
outcome. Paper presented at the International Academy of Business Disciplines Annual conference, Orlando.
Mbachie, A. E. (2005). Operation fire for fire: Operation your money or Your life: A Security
Challenge to the Nigeria Police Appraisal, The Gleaner magazine, Makurdi, St. Thomas Aquinas Major Seminary 8.
Nwankwo, U.C. (2006). Research methodology at a glance. Owerri: Uche and Uche Press Ltd.
Odekunle, F. (2004). Overview of policing in Nigeria: problems and suggestions. Ikeja-Lagos:
Cleen foundation.
Onoge, O. F. (1993). Social conflicts and crime control in colonial NigeriaPolicing Nigeria Past,
Present and Future. T. N. Tamuno; I.L Bashir; E.E.O. Alemika. and A.O. Akano Eds. Lagos: Malthouse Press Ltd.
Orobator, S. E. (1993). The political and socio-economic environment of policing since 1960.
Policing Nigeria past, present and future. T. N. Tamuno; I.L Bashir; E.E.O. Alemika. and A.O. Akano Eds. Lagos: Malthouse Press Ltd.
Punch, M. E. (1985). Conduct Unbecoming: Social Construction of Police Deviance and
Control. London: Tavistock Publications.
Punch, M. E. (2009). Police Corruption: Deviance, Accountability and Reform in Policing.
Cullompton: Willan Publishing.
Ramahi, S. (2013). Corruption in the Palestinian Authority [Online]. Middle East Monitor
(MEMO) Available: http://www.middleeastmonitor.com/
Roebuck, J. B & Barker, T (1974). A Typology of Police Corruption. Social Problems 21: 423–
37.
Tamuno, T. N. (1970). Police in Modern Nigeria 1861-1965. Ibadan: University of Ibadan Press.
Vrry, J. (2000). Metaphors” Sociology beyond societies mobiliteis for the Twenty-first Century,
New York: Routledge.
Yecho, J.I. (2005): Policing Crime or Status? A Review of police law Enforcement, Journal of
Economics and Research, Makurdi Benue State University. Vol 3 (2).











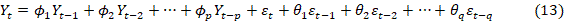
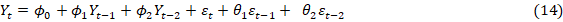
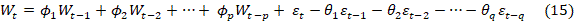









You must be logged in to post a comment.