From our childhood we are speaking daily with your family, friends, relatives but we can’t speak a good communication skills we the people who are strange to us. But few people have brilliant skill in communication. So, here are some steps to improve the communication skills.
1)BUILT A COMMUNICATION WITH EYE CONTACT
First and main steps to build the communication is eye contact. This plays a important role in the communication. Many of us do mistake while we are speaking like we don’t look at them, we use cellphone during the communication. So, first of all we should correct them and practice eye contact. Many business people use eye contact as the advantage in the negotiation for their purpose. So practice eye contact.
2) Be patience for their speech
Always be patience to the speaking partner. Patience is one of the most valuable skill in the world which may enables us to help in improve decision making, communication and power solving situation. Listen and explore them with your mind what they are taking.
PEOPLE WHO ARE GOOD COMMUNICATOR ARE THE GOOD LISTERS.
Here are some tips practising patience
Be a good listener
Be in present moment
Make smile
3)Look them with smile
When you are starting the conversation starts with smile which may boost your confidence and ensure that you will be kind. Many people things smiling may unwelcome to others but smiling will help you to better communications. Smile is the way to tell the feedback to your partner and also boost our mood.
THE GREATEST SELF IS A PEACEFUL SMILE, THAT ALWAYS SEES THE WORLD SMILING BAD
*Why are internships important?*Your might have certain questions about why one should do an internship. Well, here are some points 👇👇
◼️ *Work ex matters*– Many Job recruiters value relevant work experience more than any other qualifications while recruiting. Also, getting experience will do wonders for your confidence during any job interview.
◼️ *It allows you to apply classroom knowledge in real-life situations –* Internships give you a way to utilize your knowledge base, and expand it, by applying it in situations where the outcome is not the number of marks you score in an exam but something that could affect a whole company.
◼️ *It opens many doors –* Students get to know more opportunities to grow and make some professional connections which could open many doors for them. They can even get a recommendation letter to boost up their CV.
◼️ *Networking*- Networking is an exchange of information between people, with the ultimate goal of establishing acquaintances and relationships to advance your professional career. Networking can certainly help you find your dream career and also about not-so-common careers which can interest you!
◼️ *Earn stipend –* All the opportunities at Internshala comes with a stipend.
◼️ *Win-Win situation -* Internship opportunities not only provide you industry exposure to a particular field but also help you discover your interests and learn more about yourself. So one should never miss out on such opportunities to grow.
*Internships let you flirt with careers before you marry one*
*ATTENTION *! *Part-Time Pocket Money Internships*🥳🥳🥳🥳 campaign, where you can choose and apply to *8,000+* work from homè internships with a chance of earning a stipend upto *Rs 1.2 Lacs*. *The best part*? You can work for only *2-3 hours a day* and that is also in your favorite profile, and the registration is completely free!
For those who know about cloud or are interested about it must have heard this word once “serverless”. As confusing as it sounds it has created a lots of myths around this like
Is serverless actually server less?
Is serverless and FaaS really same?
If you are curious about this or just wanna know serverless let’s find out together. Also we will be taking some important questions like why you should learn/know serverless, does your enterprise actually need serverless? Let’s find out together.
The first thing is what is serverless-
According to cloudflare- serverless computing is a method of providing back-end services on an as-used basis.¹
Also serverless framework is free opensource framework build for developing lambda a serverless computing platform of amazon. So what serverless basically means is rather than managing your server together with application you let the server provider manage it. This way you can focus more on application you are writing. You give them the code and they will imply this on server and will charge you based on traffic and services. so serverless doesn’t means having no server but means having no hussle of servers.
Many times FaaS and serverless are taken as replaceable words but are they same?
While serverless is a broad term Serverless computing can be divided in two types
BaaS(back-end as a service)
FaaS(function as a service)
so FaaS is a type of serverless computing.
Now why should you learn/know serverless? It’s simple as it’s a growing field if you want to use it in firm, in your career or if you just want to feed your curiosity you should learn/know it.
Does you enterprise or you need it?
The big part of you decision depends on
Time- if you have time to manage back-end issue or you love doing it you can leave serverless
Money- It also depends on how well you can manage finances.
Knowledge- Also you should know you or the human resource you hold how well they have knowledge about back-end or functions or will it be better leaving on serverless.
Qwicklabs is always my #1 resource for learning something cloud, for these article too. Its bitesize lessons makes it easy to grasp or remember concept even if you are taking quest or not.
2 . Serverless full stack application on aws- serverless.com
It’s a tutorial or a course by serverless.com to teach about serverless and its implications for full stack development and various tricks to utilise it financially
It has bite-size lessons, quizzes, some exercises, cute badges, you can always look how much you learnt or can take a quiz to refurbish your knowledge but most importantly a community to help with they want to try the stuff as the content progress for better grasping.
4 . 7- best serverless courses and aws lambda courses to learn in 2021- medium
It’s a article by medium in which it explains what is serverless and why it’s important but also connects to lots of important resources to further proceed.
It’s Google cloud explaining what’s serverless and why you should use there serverless products. This article is nice for those who are new and want to get start, it has a video, some links to documentation, some other sources like there trusted partners and some examples.
7. What is serverless computing?- IBM cloud education
It’s IBM C.E. explaining serverless, it’s nice but as it’s from IBM C.E. it’s more of clearing concepts and confusions and getting little learner insight instead of promotion of service like in above article, it’s worth reading for students looking for serverless or wants to clear there basics.
It’s language is comparatively simple to above articles and it provides detail insights of serverless, if you’re jumbling in tough tech words can give this article a try.
If you are confused whom to choose MNC or startup here’s my 5 reason why it should be a startup.
Learning While you can learn and get help from your nice colleagues in MNC, at startup you can learn a lot other interesting things.
Pushing the limits As a startup they need everyone to push there limits to find there new strength as this may not be available on established MNCs, you might wanna start at a startup.
Community You might get some friends in MNC but while it comes to startup most of them wants to start, needs help and are willing to help, making it a nice community.
No boss Startup too have bosses but as they are in early phase they are more of a friend, helper and mentor, so if you are new in office work you might wanna choose startup first.
Future If your startup grows you too will get credit of it unlike in MNCs you can use it in CV and show how much it has grown and what are the role you played in its growth.
This are not the only reasons sometimes they can give you lifelong friends, experience and if you are dedicated to work, journey in startup is lot more fun.
It is said that Intense workouts without the intake of proper nutrition is a huge waste of time. Without the intake of proper nutrition, supplementation and hydration you will make little or no gains. The importance of raw materials in growth of body’s muscle mass cannot be ignored. So, today in this particular article we are going to discuss about one such nutritious compound, namely Beta-Alanine, and its top 7 supplemental sources. Before we begin, let’s find out what beta-alanine is.
What is Beta-Alanine?
Beta-Alanine is defined as a non-essential amino acid which is the only naturally occurring beta-amino acid. It is a modified version of the amino acid alanine and is produced endogenously in the liver.
Why do people take beta-alanine supplements?
Beta-alanine has been shown to enhance muscular endurance. It aids in the production of carnosine which is a compound that plays a vital role in muscle endurance in high-intensity exercise. It is commonly used for improving athletic performance and building muscles.
1. Transparent Labs BULK
Transparent Labs Beta-Alanine is the top beta-alanine for the purists. It only contains pure beta-alanine powder. There aren’t any added artificial sweeteners, colouring, or preservatives.
It delivers 4 grams of Beta-Alanine along with 18 other active ingredients in every scoop helping boost muscle power, endurance, and stamina so you can fit in those extra reps during your training session.
The only downside to this product being its price. It is relatively expensive. One another bonus is that this product is available in five flavours: Orange, Green Apple, Sour Grape, Blue Raspberry, Tropical Punch.
2. Bulk Supplements
As is evident from the name, bulk supplements is specialized in selling its products in bulk for low prices. This supplement is highly recommended because of its purity, it only contains a pure form of beta-alanine powder with no additives. It is the most cost-effective option. One downside is that unlike the other similar products, this doesn’t come with a scoop for measuring doses, which at times makes getting the required serving a bit more difficult particularly for those who are unequipped with an alternative means of measuring. Moreover, some people find the product quite sour because of the absence of flavourings and sweeteners.
3. NOW Sports Beta Alanine
NOW Sports Beta-Alanine Powder is a very simple and pure beta-alanine supplement which is manufactured by one of the biggest and best supplement companies in the market. It’s doses are effective and unflavoured.
The capsules, unlike many competitors, are vegan-friendly. The prime ingredient is CarnoSyn, beta-alanine with a quite good reputation for its purity. 750 mg of beta alanine is contained in each gelatin capsule with only a minimal number of binders and stabilizing agents.
It is found to delay muscle fatigue and helps to recover faster. Besides being an ideal option for the vegans, it is also Steroid-Free, and Quality GMP Assured product.
4. PrimaForce Beta-Alanine
PrimaForce Beta-Alanine is yet another simple supplement. It contains 2g of beta-alanine per dose, with no other ingredients. It’s a quite affordable option which offers you a loose powder form of beta alanine.
It’s manufactured by PrimaForce which is not as big or established as some of the manufacturers on this list, but is a rapidly growing supplement manufacturer based in the USA. The company states that its mission is to provide the customers with high quality and effective supplements that can help them reach their health and fitness goals.
5. Cellucor C4 Ultimate
Cellucor’s C4 is one of the most powerful pre-workouts available in the market. It is a 4th generation powerful workout boosting supplement that blends beta-alanine with branched-chain amino acids. It includes industry grade ingredients, providing 1.6 Grams of Beta-Alanine in each scoop containing 3.8 grams of the CarnoSyn Beta-Alanine formula and many other ingredients which helps to enhance endurance. It also helps offset muscle soreness and fatigue, and maximizes endurance and stamina.
The prime reason which adds to its uniqueness is that it has the only beta-alanine formula that is patented and clinically studied for its effectiveness.
6. BSN – XPLODE
This one’s another in the category of pre-workout blends that incorporate beta alanine’s performance-enhancing properties as a central part of the supplement’s benefits. It is a top-rated pre-workout supplement that provides explosive energy for explosive results. The powder is effortless to prepare providing you with 3.6 grams of beta-alanine per serving. It blends carnosine, beta-alanine and beta-alanine HCl. Moreover, the product has been purposefully unflavoured allowing for infinite stacking possibilities.The product incorporates two forms of Beta-Alanine as Beta-Alanine HCL and Carnosyn, which aids to enhance muscle growth, strength, and endurance. Xplode goes the extra mile to provide a pre-workout pump focusing on providing extreme endurance.
7.Optimum Nutrition Beta-Alanine
This is another effective supplement that can help individuals in reaching their full potential at the gym. It uses high-quality ingredients, mixed with a few micronutrients, blended in effective amounts to produce optimal results. Also, the unique addition of L-histidine and phosphates further improves the efficacy of this product helping to keep your workout performance at its prime.
It is manufactured by Optimum Nutrition, which is undoubtedly one of the best brands in the business. The prices are comparatively low which keeps it within the reach of everyone. Additionally, they also have an unflavoured option which provides a good option for those who are sceptical about flavoured supplements.
THE EXPLORATION AND ADVANTAGE OF WORKING UNDER TRAINING JOB CRITERIA
TRAINING JOB
A very important aspect to be conducted among the graduates those are well-versed in subject knowledge and practical skills as well. Upon graduation teenagers will have relevant background of all information (every edge and corner) of their course/field.
But your knowledge cannot be implemented until it is shaped and guided by advanced experts to work on real-time fields.
The first and foremost purpose of this is there are certain procedures to hold on before you start working manually just to produce the desired outcomes as per the requirements of their corporate brand.
In Guruface, you need not worry as they work under a criterion of providing essentials materials by assigning them to a by picking up best performer by monitoring their activity and fastness with perfection. You prove your talent to your mentor as you present them in a precise way.
This website aims on providing service, preparing students and mentors with their enormous coaching to work under several recognized organizations. The stream and courses are tremendous as you can feel free to ask support 24/7 from their side as they reach you at the earliest.
Clinging on to Guruface is a right choice as they offer free access without registration also engaging in sorting out issues thus creating leaders to grow the pillars of India. They have combinations of corporate and individual to fulfill each need.
This is something more advanced as you can consider, than your practical experience in institution so undergoing your training will help in better ways to work as an individual to contribute in projects or in teams.
Each one uses their own learnt knowledge on subject joined with the assist on trainings that comes under to work directly on several projects as an intern/trainee on utilization of mechanism, tools, skills, equipment also enclosed raw materials (data, incomplete projects, task to code) etc.
Benefits of working on Training Jobs
Exclusive for every problem you get a mentor support to clarify your issues, thus helps in facing hinderances during everyone’s presentation as a part of work. One of the most popular methods considered in United Kingdom, China where an advanced knowledge, company-specific skills of an employer is passed other new employees.
The main focus of this category is to put you under real-time tasks and monitor your performance according to which you solve them and create some ideas and methodology behind every assessment.
Every fresher/joiner become trainer or professional as they get trainer under the supervision experts.
The gradually inclining company can figure out ways to which you can reach your goals in a digital world like “Guruface” that has flourished in many hearts and lives of people to endeavor a journey an excellent future.
These trainings provide a vision that is created as a sample for new joiners to make them cope up and complete their tasks at the workplace. The environment becomes more familiar for you working/being as a part under the training.
The online educating platform with expertise faculties in teaching and training under several categories regarding to software or computer platform associated with other skills like music, arts, Digital marketing, preparation off Exam and much more that you will find effective.
They comprise of more than 5000 tutors with a network of affiliates of 100+ connections. You can explore a thousand groups to opt on learning with a category of 200 plus on each course.
All their benefits are utilized wiser by leading young generation to excel in them among the opponents under any field of corporate world. These briefs on them social media site is not for an advertisement just to motivate youngsters to make benefits out of the over-whelming training session with them.
As you work under a training criterion it’s like “two mangoes in a single stone” you learn the workplace and working abilities to be used under a working environment. Hence you make connections while learning as resuming to import your contacts who are kind like friends, schoolmates to spread a subsequent platform for trainings falling under learning or job category.
Informative Information on GuruFace
One can develop and build their talent that will suit as a helping hand in future of anyone’s life career. Their mentors so called ‘Gurus’ will communicate with virtual class thus connecting with you one on one by joining online.
They have tied up with atleast 10,000 networks with amateur industrialists and trainers as the quality assurance never fades by learning there. Until your course is completed as per the duration you can notice the work of every joinee/student thus predicting/analyzing each one level of capability.
The multi-famous organizations join hands with Guruface to promote and prefer you the suitable people and course thus landing you in a fruitful greenery. Mostly focused on strong collaboration that has a modifying e-learning platform from upcoming to stabilized companies.
You find a fruitful career and life if you can join among this platform/organization as a member to grasp something big as the knowledge they provide is huge and wordless. They also encourage interns by supporting them to implement the ‘wisdom they had got from them to them itself’.
Try using and suggesting this media as it only guides you to a spontaneous advanced future as your expertise your career here, hence proving your talent in big platforms or companies when you get a chance.
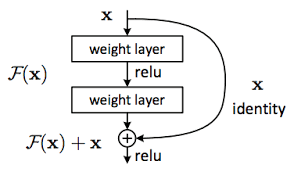
This is the last article in this series. This article is about another pre-trained CNN known as the ResNet along with an output visualization parameter known as the confusion matrix.
ResNet
This is also known as a residual network. It has three variations 51,101,151. They used a simple technique to achieve this high number of layers.
The problem in using many layers is that the input information gets changed in accordance with each layer and subsequently, the information will become completely morphed. So to prevent this, the input information is sent in again like a recurrent for every two steps so that the layers don’t forget the original information. Using this simple technique they achieved about 100+ layers.
ResNet these are the three fundamentals used throughout the network.
There are many bottlenecks like these throughout the network. Hence by this, the ResNet is able to perform well and produce good accuracy. As a matter of fact, the ResNet is the model which won the ImageNet task competition.
There are 4 layers in this architecture. Each layer has a bottleneck which comprises convolution followed by relu activation function. There are 46 convolutions, 2 pooling, 2 FC layers.
There is a particular aspect apart from the accuracy which is used to evaluate the model, especially in research papers. That method is known as the confusion matrix. It is seen in a lot of places and in the medical field it can be seen in test results. The terms used in the confusion matrix have become popularized in the anti-PCR test for COVID.
The four terms used in a confusion matrix are True Positive, True Negative, and False positive, and false negative. This is known as the confusion matrix.
True positive- both the truth and prediction are positive
True negative- both the truth and prediction are negative
False-positive- the truth is negative but the prediction is positive
False-negative- the truth is positive but the prediction is false
Out of these the false positive is dangerous and has to be ensured that this value is minimal.
We have now come to the end of the series. Hope that you have got some knowledge in this field of science. Deep learning is a very interesting field since we can do a variety of projects using the artificial brain which we have with ourselves. Also, the technology present nowadays makes these implementations so easy. So I recommend all to study and do projects using these concepts. Till then,
This article is about one of the pre-trained CNN models known as the VGG-16. The process of using a pretrained CNN is known as transfer learning. In this case, we need not build a CNN instead we can use this with a modification. The modifications are:-
Removing the top (input) and bottom (output) layers
Adding input layer with size equal to the dimension of the image
Adding output layer with size equal to number of classes
Adding additional layers (if needed)
The pre-trained model explained in this article is called the VGGNet. This model was developed by the Oxford University researchers as a solution to the ImageNet task. The ImageNet data consists of 10 classes with 1000 images each leading to 10000 images in total.
This is the architecture for VGGNet. This has been found for the CIFAR-10 dataset, a standard dataset containing 1000 classes. This was used for multiclass classification. Some modifications are made before using it for detecting OA. The output dimension is changed into 1*1*2 and the given images must be reshaped to 224*224 since this dimension is compatible with VGGNet. The dimensions and other terms like padding, stride, number of filters, dimension of filter are chosen by researchers and found optimal. In general, any number can be used in this place.
The numbers given below the figure correspond to the layer number. So the VGGNet is 13 layered and is CNN till layer 10 and the rest are FNN.
Colour index
Name
Grey
Convolution
Red
Pooling
Blue
FFN
Computations and parameters for each layer
Input
224*224 images are converted into a vector whose dimension is 224*224*3 based on the RGB value.
Layer 1-C1
This is the first convolutional layer. Here 64 filters are used.
Wi =224, P=1, S=1, K=64, f=3*3
Wo =224 (this is the input Wi for the next layer)
Dim= 224*224*64
Parameter= 64*3*3= 576
Layer 2-P1
This is the first pooling layer
Wi =224, S=2, P=1, f=3
Wo=112 (this is the input Wi for the next layer)
Dim= 112*112*3
Parameter= 0
Layer 3-C2C3
Here two convolutions are applied. 128 filters are used.
Wi =112, P=1, S=1, K=64, f=3
Wo=112 (this is the input Wi for the next layer)
Dim= 112*112*128
Parameter= 128*3*3=1152
Layer 4- P2
Second pooling layer
Wi =112, P=1, S=2, f=3*3
Wo =56 (this is the input Wi for the next layer)
Dim= 56*56*3
Parameter= 0
Layer 5- C4C5C6
Combination of three convolutions
Wi =56, P=1, S=1, K=256, f=3*3
Wo = 56 (this is the input Wi for the next layer)
Dim= 224*224*64
Parameter= 64*3*3= 576
Layer 6-P3
Third pooling layer
Wi =56, P=1, S=2, f=3*3
Wo =28 (this is the input Wi for the next layer)
Dim= 28*28*3
Parameter= 0
Layer 7-C7C8C9
Combination of three convolutions
Wi =28, P=1, S=1, K=512, f=3*3
Wo =28 (this is the input Wi for the next layer)
Dim= 28*28*512
Parameter= 512*3*3= 4608
Layer 8-P4
Fourth pooling layer
Wi =28, P=1, S=2, f=3*3
Wo =14 (this is the input Wi for the next layer)
Dim= 14*14*3
Parameter= 0
Layer 9-C10C11C12
Last convolution layer, Combination of three convolutions
Wi =14, P=1, S=1, K=512, f=3*3
Wo =14 (this is the input Wi for the next layer)
Dim= 14*14*512
Parameter= 512*3*3= 4608
Layer 10-P5
Last pooling layer and last layer in CNN
Wi =14, P=1, S=2, f=3*3
Wo =7 (this is the input Wi for the next layer)
Dim= 7*7*3
Parameter= 512*3*3= 4608
With here the CNN gets over. So a complex 224*224*3 boil down to 7*7*3
Trends in CNN
As the layer number increases,
The dimension decreases.
The filter number increases.
Filter dimension is constant.
In convolution
Padding of 1 and stride of 1 to transfer original dimensions to output
In pooling
Padding of 1 and stride of 2 are used in order to half the dimensions.
Layer 11- FF1
4096 neurons
Parameter= 512*7*7*4096=102M
Wo= 4096
Layer 12- FF2
4096 neurons
Wo= 4096
Parameter= 4096*4096= 16M
Output layer
2 classes
non-osteoarthritic
osteoarthritic
Parameter= 4096*2= 8192
Parameters
Layer
Value of parameters
Convolution
16M
FF1
102M
FF2
16M
Total
134M
It takes a very large amount of time nearly hours for a machine on CPU to learn all the parameters. Hence they came with speed enhancers like faster processors known as GPU Graphic Processing Unit which may finish the work up to 85% faster than CPU.
The previous article was about the padding, stride, and parameters of CNN. This article is about the pooling and the procedure to build an image classifier.
Pooling
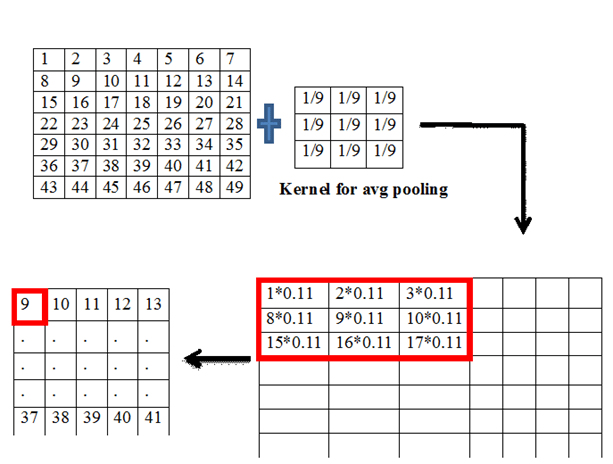
This is another aspect of CNN. There are different types of pooling like min pooling, max pooling, avg pooling, etc. the process is the same as before i.e. the kernel vector slides over the input vector and does computations on the dot product. If a 3*3 kernel is considered then it is applied over a 3*3 region inside the vector, it finds the dot product in the case of convolution. The same in pooling finds a particular value and substitutes that value in the output vector. The kernel value decides the type of pooling. The following table shows the operation done by the pooling.
Type of pooling
The value seen in the output layer
Max pooling
Maximum of all considered cells
Min pooling
Minimum of all considered cells
Avg pooling
Average of all considered cells
The considered cells are bounded within the kernel dimensions.
The pictorial representation of average pooling is shown above. The number of parameters in pooling is zero.
Convolution and pooling are the basis for feature extraction. The vector obtained from this step is fed into an FFN which then does the required task on the image.
Features of CNN
Sparse connectivity
Weight sharing.
Feature extraction-CNN classifier-FNN
In general, CNN is first then FFN is later. But the order or number or types of convolution and pooling can vary based on the complexity and choice of the user.
Already there are a lot of models like VGGNet, AlexNet, GoogleNet, and ResNet. These models are made standard and their architecture has been already defined by researchers. We have to reshape our images in accordance with the dimensions of the model.
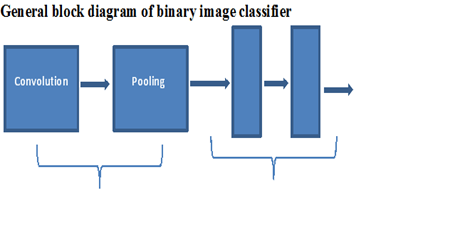
General procedure to build an image classifier using CNN
Obtain the data in the form of image datasets.
Set the output classes for the model to perform the classification on.
Transform or in specific reshape the dimension of the images compatible to the model. The image size maybe 20*20 but the model accepts only 200*200 images; then we must reshape them to that size.
Split the given data into training data and evaluation data. This is done by creating new datasets for both training and validation. More images are required for training.
Define the model used for this task.
Roughly sketch the architecture of the network.
Determine the number of convolutions, pooling etc. and their order
Determine the dimensions for the first layer, padding, stride, number of filters and dimensions of filter.
Apply the formula and find the output dimensions for the next layer.
Repeat 5d till the last layer in CNN.
Determine the number of layers and number of neurons per layer and parameters in FNN.
Sketch the architecture with the parameters and dimension.
Incorporate these details into the machine.
Or import a predefined model. In that case the classes in the last layer in the FNN must be replaced with ‘1’ for binary classification or with the number of classes. This is known as transfer learning.
Train the model using the training dataset and calculate the loss function for periodic steps in the training.
Check if the machine has performed correctly by comparing the true output with model prediction and hence compute the training accuracy.
Test the machine with the evaluation data and verify the performance on that data and compute the validation accuracy.
If both the accuracies are satisfactory then the machine is complete.
The previous article was about the process of convolution and its implementation. This article is about the padding, stride and the parameters involved in a CNN.
We have seen that there is a reduction of dimension in the output vector. A technique known as padding is done to preserve the original dimensions in the output vector. The only change in this process is that we add a boundary of ‘0s’ over the input vector and then do the convolution process.
Procedure to implement padding
To get n*n output use a (n+2*n+2) input
To get 7*7 output use 9*9 input
In that 9*9 input fill the first row, first column, last row and last column with zero.
Now do the convolution operation on it using a filter.
Observe that the output has the same dimensions as of the input.
Zero is used since it is insignificant so as to keep the output dimension without affecting the results
Here all the elements in the input vector have been transferred to the output. Hence using padding we can preserve the originality of the input. Padding is denoted using P. If P=1 then one layer of zeroes is added and so on.
It is not necessary that the filter or kernel must be applied to all the cells. The pattern of applying the kernel onto the input vector is determined using the stride. It determines the shift or gaps in the cells where the filter has to be applied.-
S=1 means no gap is created. The filter is applied to all the cells.
S=2 means gap of 1. The filter is applied to alternative cells. This halves the dimensions on the output vector.
This diagram shows the movement of filter on a vector with stride of 1 and 2. With a stride of 2; alternative columns are accessed and hence the number of computations per row decreases by 2. Hence the output dimensions reduce while use stride.
The padding and stride are some features used in CNN.
Parameters in a convolution layer
The following are the terms needed for calculating the parameter for a convolution layer.
Input layer
Width Wi – width of input image
Height Hi – height of input image
Depth Di – 3 since they follow RGB
We saw that 7*7 inputs without padding and stride along with 3*3 kernels gave a 5*5 output. It can be verified using this calculation.
The role of padding can also be verified using this calculation.
The f is known as filter size. It can be a 1*1, 3*3 and so on. It is a 1-D value so the first value is taken. There is another term K which refers to the number of kernels used. This value is fixed by user.
These values are similar to those of w and b. The machine learns the ideal value for these parameters for high efficiency. The significance of partial connection or CNN can be easily understood through the parameters.
Consider the same example of (30*30*3) vector. The parameter for CNN by using 10 kernels will be 2.7 million. This is a large number. But if the same is done using FNN then the parameters will be at least 100 million. This is almost 50 times that of before. This is significantly larger than CNN. The reason for this large number is due to the full connectivity.
Communication can make or break your efforts to connect with your team, manage and coordinate initiatives, and build trust within your organization. Great pioneers speak with a worker first focal point. They communicate based on the needs and preferences of their team members and seek to listen to and understand the employee experience.
2.Have a dream for what’s to come/have a vision
Vision gives center, inspiration, and course to travel through change and snags. Great pioneers have a reasonable vision and can express the way ahead to their group. Leaders ought to have the option to interface the work on the ground to the master plan and give the explanation for all that they do.
3. Understanding what others want
For dealing with agroup one should understand what sorts of jobs are reasonable for every single individual from the group. The pioneer ought to have the capacity to use every individuals potential to the most extreme. Each colleague ought to have singular objectives fell down from a solitary Goal and vision of the group. Colleagues accordingly feel that their commitments are significant in accomplishing the goal/Goal.
4.Consider themselves responsible
Great pioneers consider themselves responsible and are continually attempting to improve and advance. They are perpetually discontent with business as usual. Responsibility and consistent improvement require a guarantee to looking for and following up on criticism, gaining from errors, and course remedying.
5.Show appreciation
A grateful pioneer is an powerful pioneer. Appreciation brings positive collaborations and association, expands commitment, and fabricates flexibility. Grateful leaders comprehend that achievement is a collaboration and they make a point to perceive the work and commitments of their group.
The previous article was about the procedure to develop a deep learning network and introduction to CNN. This article concentrates on the process of convolution which is the process of taking in two images and doing a transformation to produce an output image. This process is common in mathematics and signals analysis also. The CNN’s are mainly used to work with images.
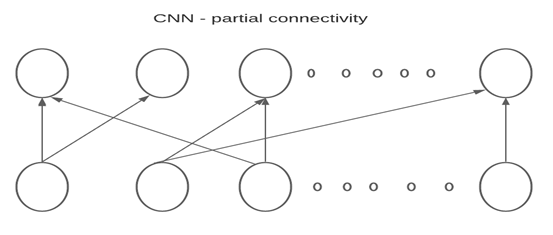
In the CNN partial connection is observed. Hence all the neurons are not connected to those in the next layer. So the number of parameters reduces leading to lesser computations.
Sample connection is seen in CNN.
Convolution in mathematics refers to the process of combining two different functions. With respect to CNN, convolution occurs between the image and the filter or kernel. Convolution itself is one of the processes done on the image.
Here also the operation is mathematical. It is a kind of operation on two vectors. The input image gets converted into a vector based on colour and dimension. The kernel or filter is a predefined vector with fixed values to perform various functions onto the image.
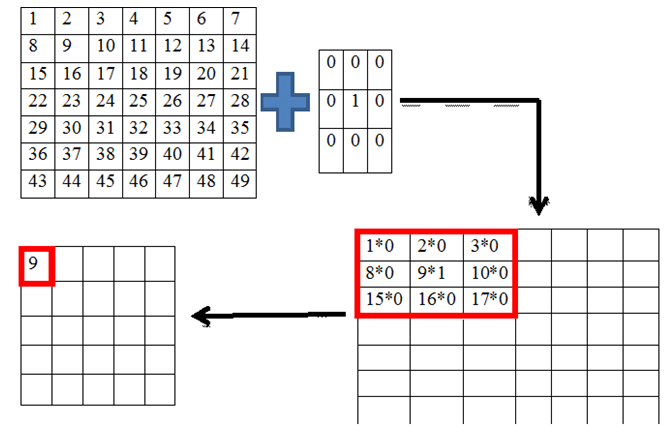
Process of convolution
The kernel or filter is chosen in order of 1*1, 3*3, 5*5, 7*7, and so on. The given filter vector slides over the image and performs dot product over the image vector and produces an output vector with the result of each 3*3 dot product over the 7*7 vector.
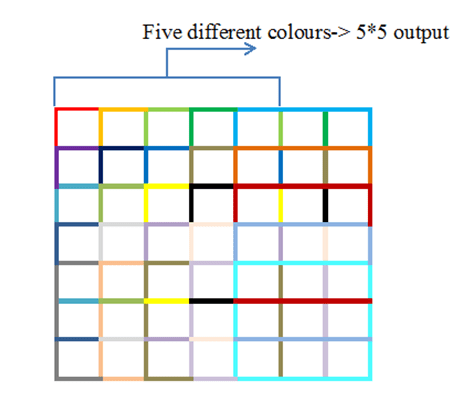
A 3*3 kernel slides over the 7*7 input vector to produce a 5*5 output image vector. The reason for the reduction in the dimension is that the kernel has to do dot product operation on the input vector-only with the same dimension. I.e. the kernel slides for every three rows in the seven rows. The kernel must perfectly fit into the input vector. All the cells in the kernel must superimpose onto the vector. No cells must be left open. There are only 5 ways to keep a 3-row filter in a 7-row vector.
This pictorial representation can help to understand even better. These colors might seem confusing, but follow these steps to analyze them.
View at the first row.
Analyse and number the different colours used in that row
Each colour represents a 3*3 kernel.
In the first row the different colours are red, orange, light green, dark green and blue.
They count up to five.
Hence there are five ways to keep a 3 row filter over a 7 row vector.
Repeat this analysis for all rows
35 different colours will be used. The math is that in each row there will be 5 combinations. For 7 rows there will be 35 combinations.
The colour does not go beyond the 7 rows signifying that kernel cannot go beyond the dimension of input vector.
These are the 35 different ways to keep a 3*3 filter over a 7*7 image vector. From this diagram, we can analyse each row has five different colours. All the nine cells in the kernel must fit inside the vector. This is the reason for the reduction in the dimension of output vector.
Procedure to implement convolution
Take the input image with given dimensions.
Flatten it into 1-D vector. This is the input vector whose values represent the colour of a pixel in the image.
Decide the dimension, quantity and values for filter. The value in a filter is based on the function needed like blurring, fadening, sharpening etc. the quantity and dimension is determined by the user.
Take the filter and keep it over the input vector from the first cell. Assume a 3*3 filter kept over a 7*7 vector.
Perform the following computations on them.
5a. take the values in the first cell of the filter and the vector.
5b. multiply them.
5c. take the values in the second cell of the filter and the vector.
5d. multiply them.
5e. repeat the procedure till the last cell.
5f. take the sum for all the nine values.
Place this value in the output vector.
Using the formula mentioned later, find the dimensions of the output vector.
The previous article was on algorithm and hyper-parameter tuning. This article is about the general steps for building a deep learning model and also the steps to improve its accuracy along with the second type of network known as CNN.
General procedure to build an AI machine
Obtain the data in the form of excel sheets, csv (comma separated variables) or image datasets.
Perform some pre-processing onto the data like normalisation, binarisation etc. (apply principles of statistics)
Split the given data into training data and testing data. Give more preference to training data since more training can give better accuracy. Standard train test split ratio is 75:25.
Define the class for the model. Class includes the initialisation, network architecture, regularisation, activation functions, loss function, learning algorithm and prediction.
Plot the loss function and interpret the results.
Compute the accuracy for both training and testing data and check onto the steps to improve it.
Steps to improve the accuracy
Increase the training and testing data. More data can increase the accuracy since the machine learns better.
Reduce the learning rate. High learning rate often affects the loss plot and accuracy.
Increase the number of iterations (epochs). Training for more epochs can increase the accuracy
Hyper parameter tuning. One of the efficient methods to improve the accuracy.
Pre-processing of data. It becomes hard for the machine to work on data with different ranges. Hence it is recommended to standardise the data within a range of 0 to 1 for easy working.
These are some of the processes used to construct a network. Only basics have been provided on the concepts and it is recommended to learn more about these concepts.
Implementation of FFN in detecting OSTEOARTHRITIS (OA)
Advancements in the detection of OA have occurred through AI. Technology has developed where machines are created to detect OA using the X-ray images from the patient. Since the input given is in the form of images, optimum performance can be obtained using CNN’s. Since the output is binary, the task is binary classification. A combination of CNN and FFN is used. CNN handles feature extraction i.e. converting the image into a form that is accepted by the FFN without changing the values. FFN is used to classify the image into two classes.
CNN-convolutional neural network
The convolutional neural network mainly works on image data. It is used for feature extraction from the image. This is a partially connected neural network. Image can be interpreted by us but not by machines. Hence they interpret images as a vector whose values represent the color intensity of the image. Every color can be expressed as a vector of 3-D known as RGB- Red Green Blue. The size of the vector is equal to the dimensions of the image.
This type of input is fed into the CNN. There are several processing done to the image before classifying it. The combination of CNN and FNN serves a purpose for image classification.
Problems are seen in using FFN for image
We have seen earlier that the gradients are chain rule of gradient at different layers. For image data, large number of layers in order of thousands may require. It can result in millions of parameters. It is very tedious to find the gradient for the millions of these parameters.
Using FFN for image data can often overfit the data. This may be due to the large layers and large number of parameters.
The previous article dealt with the networks and the backpropagation algorithm. This article is about the mathematical implementation of the algorithm in FFN followed by an important concept called hyper-parameter tuning.
In this FFN we apply the backpropagation to find the partial derivative of the loss function with respect to w1 so as to update w1.
Hence using backpropagation the algorithm determines the update required in the parameters so as to match the predicted output with the true output. The algorithm which performs this is known as Vanilla Gradient Descent.
The way of reading the input is determined using the strategy.
Strategy
Meaning
Stochastic
One by one
Batch
Splitting entire input into batches
Mini-batch
Splitting batch into batches
The sigmoid here is one of the types of the activation function. It is defined as the function pertaining to the transformation of input to output in a particular neuron. Differentiating the activation function gives the respective terms in the gradients.
There are two common phenomena seen in training networks. They are
Under fitting
Over fitting
If the model is too simple to learn the data then the model can underfit the data. In that case, complex models and algorithms must be used.
If the model is too complex to learn the data then the model can overfit the data. This can be visualized by seeing the differences in the training and testing loss function curves. The method adopted to change this is known as regularisation. Overfit and underfit can be visualized by plotting the graph of testing and training accuracies over the iterations. Perfect fit represents the overlapping of both curves.
Regularisation is the procedure to prevent the overfitting of data. Indirectly, it helps in increasing the accuracy of the model. It is either done by
Adding noises to input to affect and reduce the output.
To find the optimum iterations by early stopping
By normalising the data (applying normal distribution to input)
By forming subsets of a network and training them using dropout.
So far we have seen a lot of examples for a lot of procedures. There will be confusion arising at this point on what combination of items to use in the network for maximum optimization. There is a process known as hyper-parameter tuning. With the help of this, we can find the combination of items for maximum efficiency. The following items can be selected using this method.
Network architecture
Number of layers
Number of neurons in each layer
Learning algorithm
Vanilla Gradient Descent
Momentum based GD
Nesterov accelerated gradient
AdaGrad
RMSProp
Adam
Initialisation
Zero
He
Xavier
Activation functions
Sigmoid
Tanh
Relu
Leaky relu
Softmax
Strategy
Batch
Mini-batch
Stochastic
Regularisation
L2 norm
Early stopping
Addition of noise
Normalisation
Drop-out
All these six categories are essential in building a network and improving its accuracy. Hyperparameter tuning can be done in two ways
Based on the knowledge of task
Random combination
The first method involves determining the items based on the knowledge of the task to be performed. For example, if classification is considered then
Activation function- softmax in o/p and sigmoid for rest
Initialisation- zero or Xavier
Strategy- stochastic
Algorithm- vanilla GD
The second method involves the random combination of these items and finding the best combination for which the loss function is minimum and accuracy is high.
Hyperparameter tuning would already be done by researchers who finally report the correct combination of items for maximum accuracy.






























You must be logged in to post a comment.